
⚡Cyber Crime & Confusion Matrix⚡
What is Cyber Crime?
Cybercrime, also called computer crime, the use of a computer as an instrument to further illegal ends, such as committing fraud, trafficking in child pornography and intellectual property, stealing identities, or violating privacy.
Types of Cyber Crime :-

- Phishing :- using fake email messages to get personal information from internet users;
- Misusing personal information (identity theft)
- Hacking :- shutting down or misusing websites or computer networks
- Spreading hate and inciting terrorism
- Grooming :- making sexual advances to minors.
Nowadays, all digital devices (including computers, tablets, and smartphones) are connected to the internet. In theory, cyber criminals could bring a large part of the Netherlands to a halt. The government rightly takes cybercrime very seriously, and we are working hard to fight it.
Now, let’s talk about Confusion matrix :-
What is Confusion matrix?
A confusion matrix is a table that is often used to describe the performance of a classification model (or classifier) on a set of test data for which the true values are known. The confusion matrix itself is relatively simple to understand, but the related terminology can be confusing.
Types of errors :-
Let’s understand TP, FP, FN, TN in terms of pregnancy analogy :-

True Positive:
Interpretation: You predicted positive and it’s true.
You predicted that a woman is pregnant and she actually is.
True Negative:
Interpretation: You predicted negative and it’s true.
You predicted that a man is not pregnant and he actually is not.
False Positive (Type 1 Error) :-
Interpretation: You predicted positive and it’s false.
You predicted that a man is pregnant but he actually is not.
False Negative (Type 2 Error) :-
Interpretation: You predicted negative and it’s false.
You predicted that a woman is not pregnant but she actually is.
Accuracy and Components of Confusion Matrix :-
To find how accurate our model is, we use the following metrics:
- Precision: Precision is used to calculate the model’s ability to classify positive values correctly. It is the true positives divided by the total number of predicted positive values.
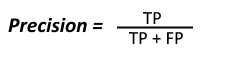
- Accuracy: Accuracy is used to find the portion of correctly classified values. It tells us how often our classifier is right. It is the sum of all true values divided by total values.
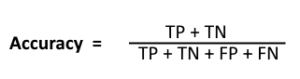
- Recall: It is used to calculate the model’s ability to predict positive values. It is the true positives divided by the total number of actual positive values.
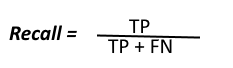
- F1-Score: It is the harmonic mean of Recall and Precision. It is useful when you need to take both Precision and Recall into account.
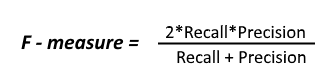
The basic definitions for Regression and classification we use in machine learning for confusion matrix.
Regression :-
Regression (or prediction) is simple. The knowledge about the existing data is utilized to have an idea of the new data. Take an example of house prices prediction. In cybersecurity, it can be applied to fraud detection. The features (e.g., the total amount of suspicious transaction, location, etc.) determine a probability of fraudulent actions.
Classification :-
Classification is also straightforward. Imagine you have two piles of pictures classified by type (e.g., dogs and cats). In terms of cybersecurity, a spam filter separating spams from other messages can serve as an example. Spam filters are probably the first ML approach applied to Cybersecurity tasks.
Conclusions :-
Machine learning techniques have proven to be beneficial for the whole security industry. However, the application of machine learning is often limited by the lack of standardized datasets, overfitting issues, the architecture cost, and so on. Therefore, it is important to apply and design new approaches to maintain the benefits of machine learning algorithms while addressing the limitations in practice. To facilitate law enforcement officials for saving humanity and for the purpose of envisaging cyber crimes, data mining algorithms and visualization techniques were utilized.
The developed cyber crime analysis tool affords a framework for visualizing the diverse cyber crime types and cyber crime prone areas in India and investigating them by data mining algorithms using the Google Maps. This task facilitates the law enforcement officials to scrutinize the cyber crime networks by means of interactive visualizations. The interactive and visual aspect relevance will be supportive in exposure and discerning the cyber crime prototypes. From the performance evaluation of existing and proposed classifiers, Enhanced Random Forest acquired 99.58% of accuracy rate with less computation time than Naïve Bayes.
Thank you for reading my article….!!!!😊
My LinkedIn Profile :- https://www.linkedin.com/in/sunil-sirvi/
